在Redis中,数据的过期可分为两种,一种是主动过期淘汰,一种是lazy方式淘汰。
- 主动过期淘汰就是在Redis中定时任务主动对数据进行采样,判断数据是否过期
- lazy淘汰就是在用户访问时,进行数据过期检查
还有一种情况是,当数据达到内存上限后,会尝试根据内存淘汰策略强制对key进行删除。
但是线上出现了一种比较奇怪的现象,在监控上查看最近几天的数据,master节点上的表现是在0点过后,数据会在10分钟内全部淘汰,key数量从4000+w淘汰到300w。
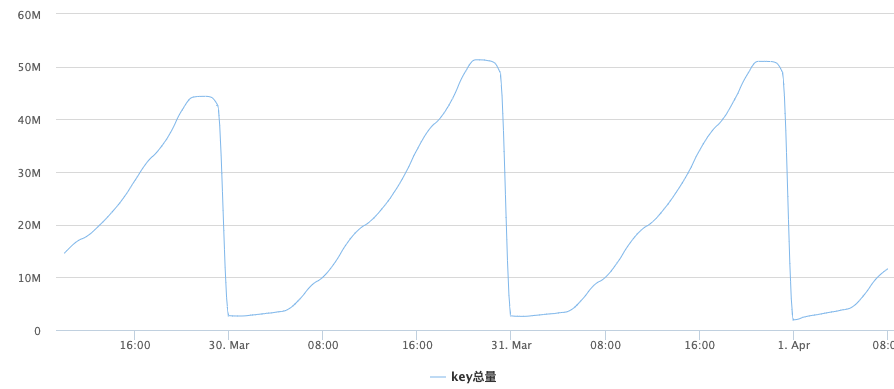
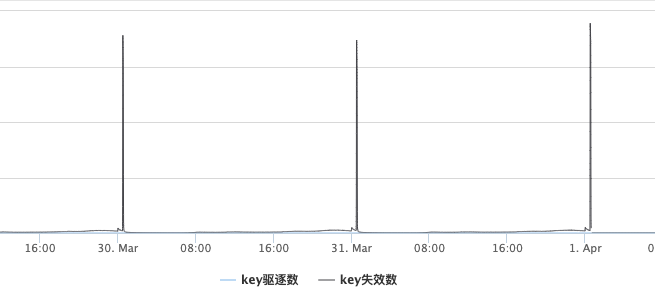
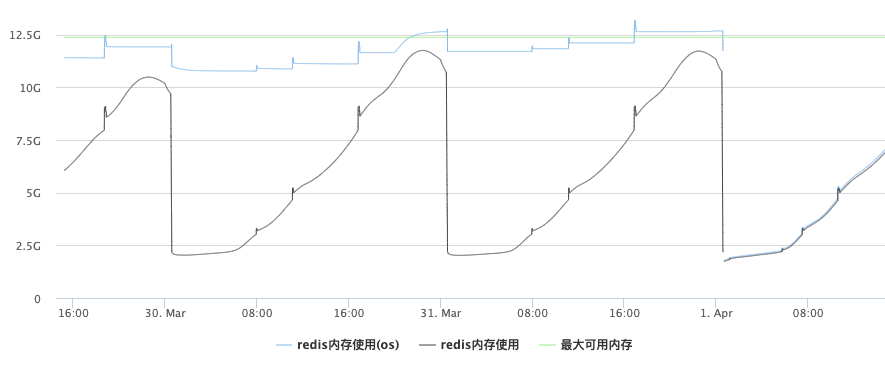
此时并没有达到Redis的最大内存限制,并没有发生强制key驱逐,如果是按正常的逻辑,发生这种大规模同时过期的场景可能会是:
- 数据key设置了相同的过期时间,把前一天的数据全部过期,并且过期时间设置了一个统一或相近的时间。
- 用户请求大量访问了已经过期的key,触发了数据的lazy过期检查,被动删除了过期的key。
但是实例的qps是稳定下降的,并且总qps也没有达到上图中数据过期的速度。
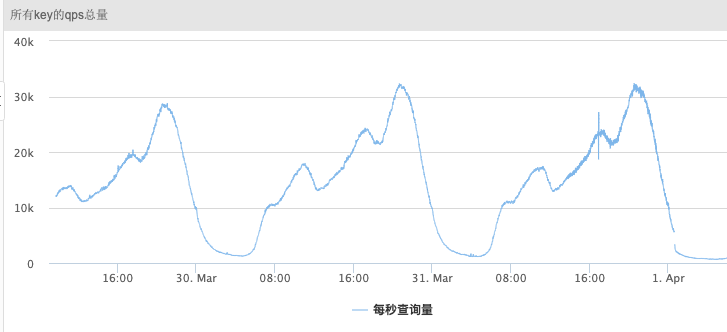
如果是lazy方式触发,按当时的qps计算,10分钟最多能淘汰key数量:5000*60*10=3000000,无法达到10分钟内把4000w key过期的速度。
真正的原因在于,在Redis的实现中,数据的主动过期虽然是定时任务中采样执行,但是会根据数据过期的不同场景触发不同定时任务执行。
在Redis中,定时任务主动过期分为ACTIVE_EXPIRE_CYCLE_FAST和ACTIVE_EXPIRE_CYCLE_SLOW两种类型。
SLOW方式是通常的正常触发方式,其执行的时机是在serverCron时,serverCron以hz频率来执行, 默认情况下,在执行过程中,会以25% cpu的限制来执行,但是在单次采样过程中,会计算实际过期key/采样key*100%是否大于10,如果低于10,则跳出循环。
而FAST方式是在有大量的过期key时,为了加快过期key的删除,采用的比较激进的主动过期方式,其执行周期在beforeSleep中,在每次事件aeMain循环中,都会尝试调用快速的数据过期检查,但是在数据过期比例不高于10%的情况下,会直接返回退出,不会继续进行快速数据过期检查。虽然可以看到,在这种方式下,每个调用迭代的时间限制在1ms左右,避免阻塞产生长耗时,但是在大流量的情况下,事件循环非常活跃,所以快速数据过期检查调用次数也会很频繁。
所以如果key几乎设置了相同的过期时间,当过期时间来临,redis通过采样会发现大部分数据已经过期,会触发快速的数据过期,过期数据被及时清理。