1. LRU
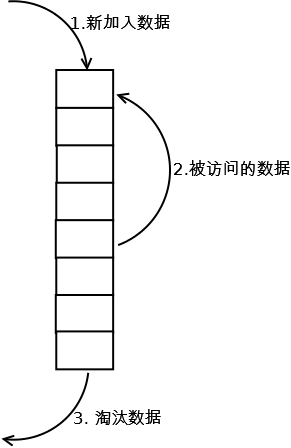
实现最简单的lru实现,其中保存的是最近一段时间访问的数据,当一个新数据被访问,数据会被加入队列头,如果队列超过长度限制,就在尾部淘汰;如果访问的数据在队列,则将其重新移到队头。
因为LRU的核心思想是:如果数据最近被访问过,那么将来被访问的几率也更高。
实现简单,但是存在LRU污染,偶发性或批量的操作会导致LRU命中率急剧下降。
2. LRU-K
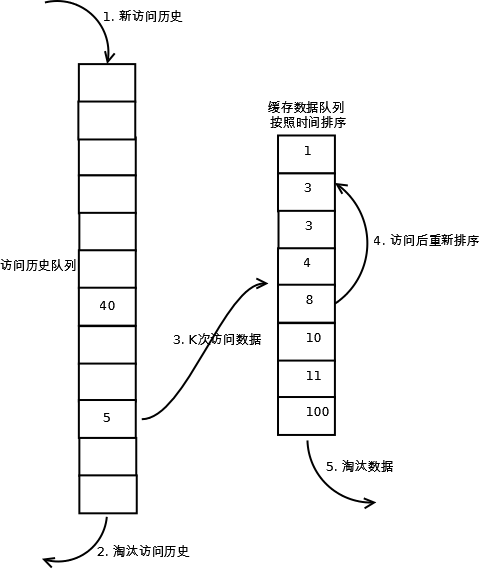
与LRU不同的是,LRU-K是在数据访问达到K后,将访问历史队列中的数据移动到LRU队列中。
LRU-K可以避免偶发性访问带来的LRU污染,能够提高LRU命中率。
需要额外维护一份最近访问数据的被访问次数的历史队列。
LRU-2在实际应用中验证效果最优。
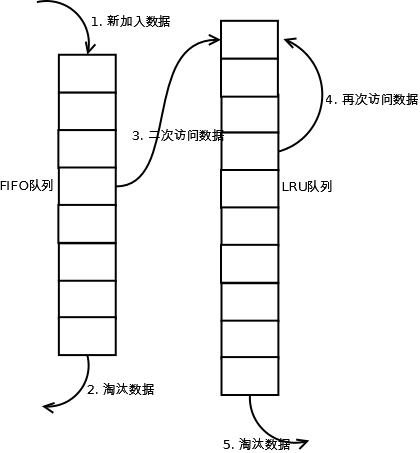
3. 双队列
类似LRU-2,但是实现上比LRU-2简单,将访问历史计数队列改成了一个FIFO的队列,实现上成本更低。
4. 多队列
根据数据访问频率划分多个队列,不同队列具有不同优先级。
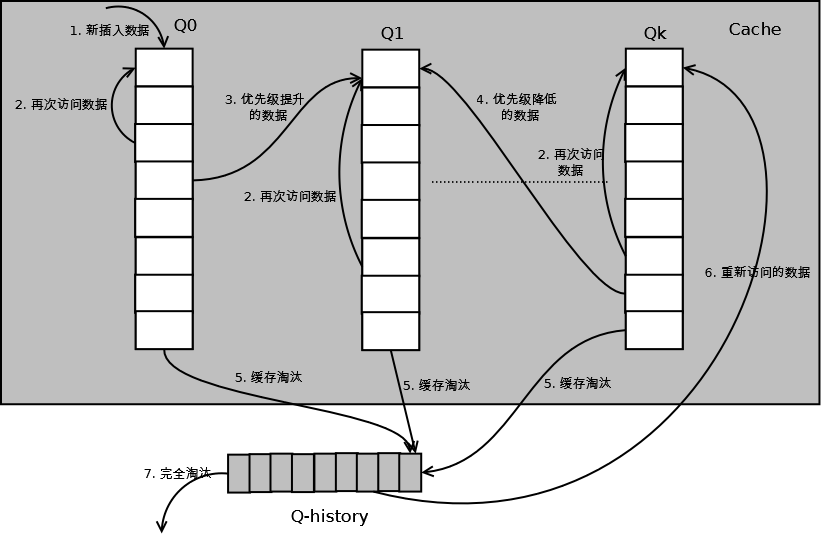
- 新数据访问,会插入Q0队列。
- 每个队列按LRU算法管理。
- 数据访问达到一定次数,会提升优先级,数据从低一级队列删除,加入高一级队列头。
- 数据特定时间内没有被访问,会降低优先级,数据从高一级队列移动到低一级队列头。
- 数据会被定时扫描。
- Q-history中的数据历史访问频率信息被清空,重新加入队列时要重新计数。
总结
复杂度:LRU-2 > MQ(2) -> 2Q > LRU