一. 背景
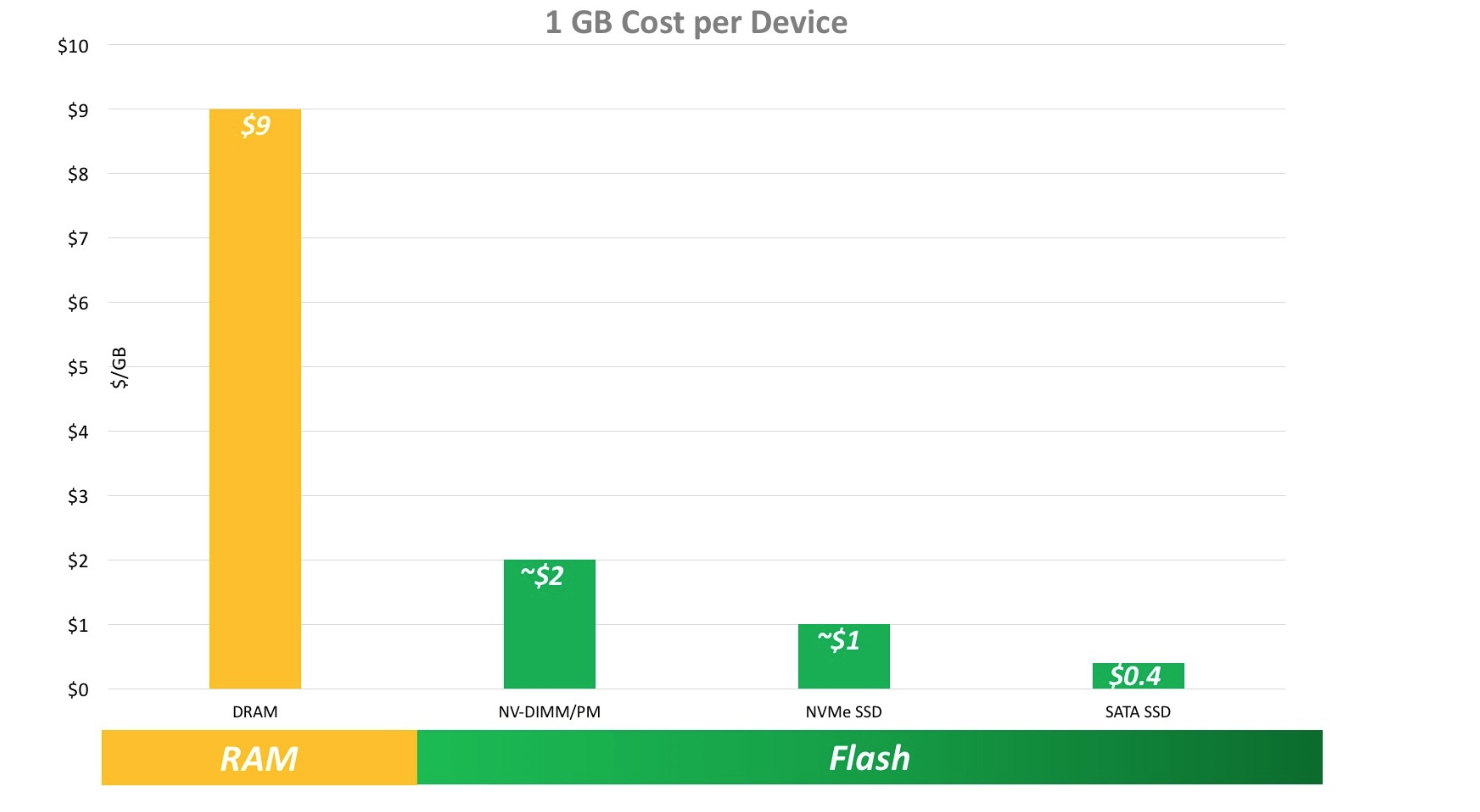
随着硬件的发展,持久化存储的速度得以提升,但是硬件成本相比内存单位的成本会有大幅度下降,并且全内存缓存存储理想应用场景是随机高速访问,而实际的应用场景中,数据访问频率不一致,数据存在冷热区分,热数据放在内存能加速访问,冷数据理应通过一定置换算法,在合适的情况下置换到持久化存储,节省成本。
二. 数据冷热分离目标
对数据按访问频率进行统计,有效标记冷热数据,后续访问过程中,根据数据冷热变化,将数据在内存和持久化存储之间移动。
- 大幅提升实例容量
- 降低单位容量成本
- 大部分应用场景可以保证性能
- 客户端连接在冷热数据交换时不会互相影响
三. 现有系统调研
3.1 SSDB
- 无冷热数据分离
- 底层采用LevelDB或RocksDB引擎
- 实现了多种数据结构
- C++实现
3.2 LedisDB
- 无冷热数据分离
- 底层采用LevelDB或RocksDB等
- 实现了多种数据结构
- Golang实现
3.3 Pika
- 无冷热数据分离
- 底层采用RocksDB引擎
- 使用第三方模块实现多种数据结构
- C++实现
- 支持多主模式,无数据一致性保证
- 360内部大规模使用
3.4 Tidis

- 无冷热数据分离
- 底层存储tikv,存储引擎为RocksDB
- 支持多种数据结构
- golang实现
- 计算存储分离
- 水平自动扩展、高可用
- 数据更新乐观锁,热点数据更新冲突需要重试
- 分布式事务,latancy较高
3.5 swapdb

- 有冷热数据分离
- 定制redis和ssdb服务组合
- ssdb和redis通过socket通信,每次数据调度需要两次网络交互
- 冷热数据LFU算法统计
- 无规模化应用
- 无人维护状态
3.6 阿里redis混合存储
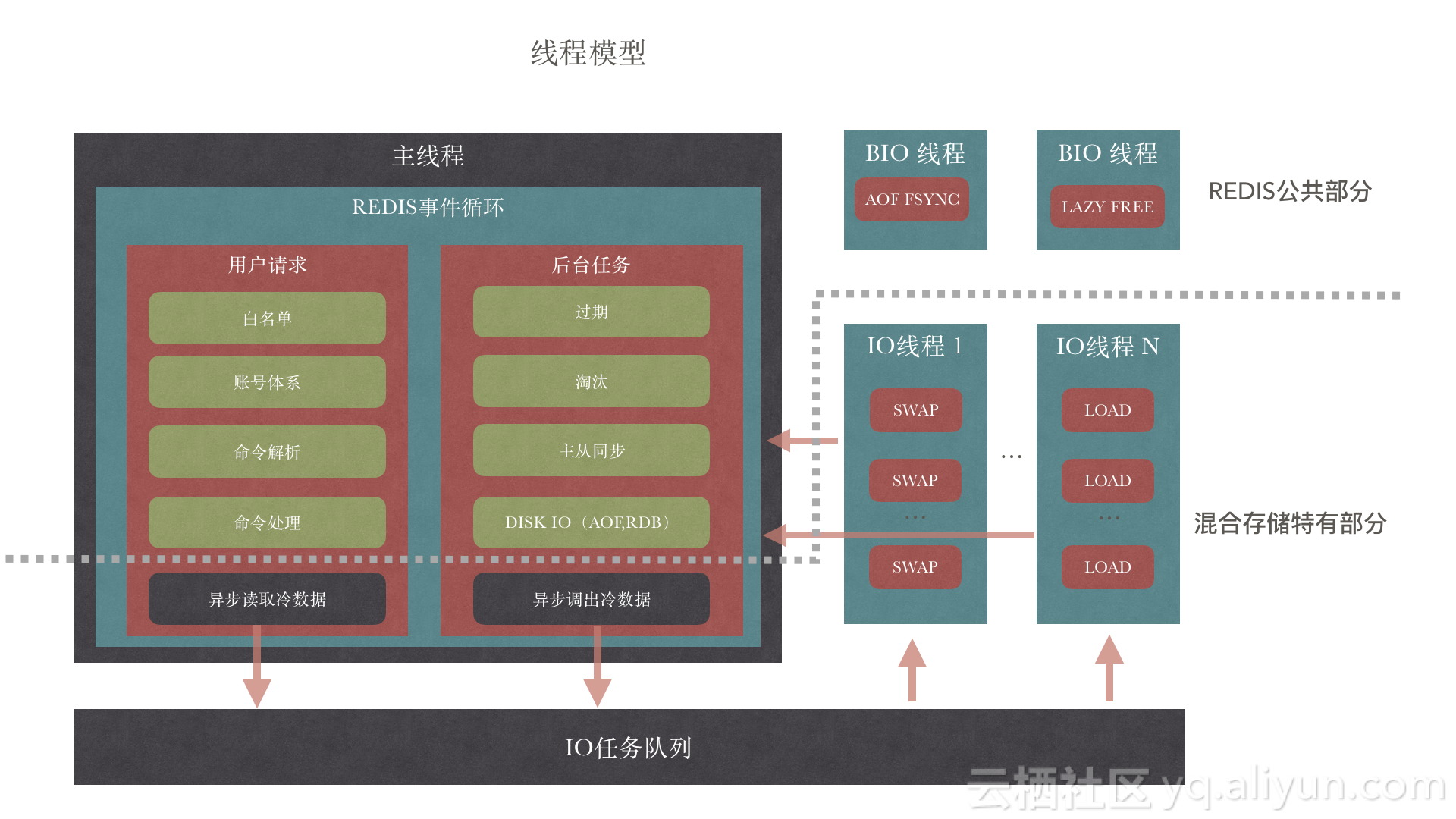
- 后端采用定制的rocksdb存储和用户态文件系统,压榨性能
- 超过内存阈值,尝试进行持久化key
- 异步线程IO处理
3.7 redis enterprise

两年前提供,官方文档描述的实现和阿里redis混合存储总体一致。
3.8 Anna
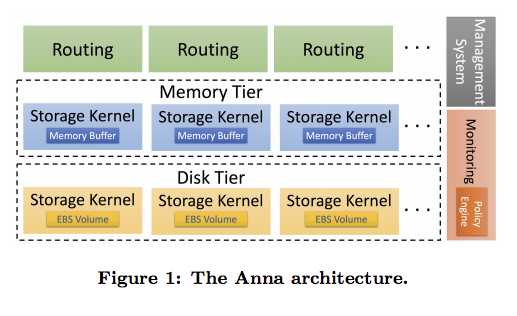
- 伯克利出品
- 冷热数据分离
- 不同层次节点相互独立
- 通过监控的策略组件对数据进行冷热迁移
- 只支持kv
- 基于aws部署
- 支持热点key流量打散,CRDT数据结构冲突解决
3.8 小结
持久化存储容量一般是内存容量的10倍以上,将部分冷数据从内存置换到持久化存储,可以提升单实例所能承载数据量的上限。在存储引擎的计划选择上选择经过大量工程验证的RocksDB,其特性如下:
- 暴露参数多,tuning空间大
- LSM Tree,顺序写,对写操作优化
- 对SSD友好,避免频繁GC
- 大量工程验证,稳定可靠
- 写性能很好,并且稳定
四. 冷热分离实现概要
虽然都是快速设备+慢速设备,冷热数据分离与cache场景不同在于:
- 冷热数据分离:快设备为主,慢速设备是对快速的设备的扩展。读写都是直接访问快速设备,后台任务将数据部分置换到慢速设备,热数据读取写入速度快。
- cache场景:慢速设备为主,快速设备是对慢速设备中小部分数据的缓存,数据的每次更新需要更新慢速设备和快速设备,热数据只能覆盖读取操作,写入操作慢。
冷热数据分离整体实现逻辑与redis商业版和阿里混合存储类似。
4.1 整体模型
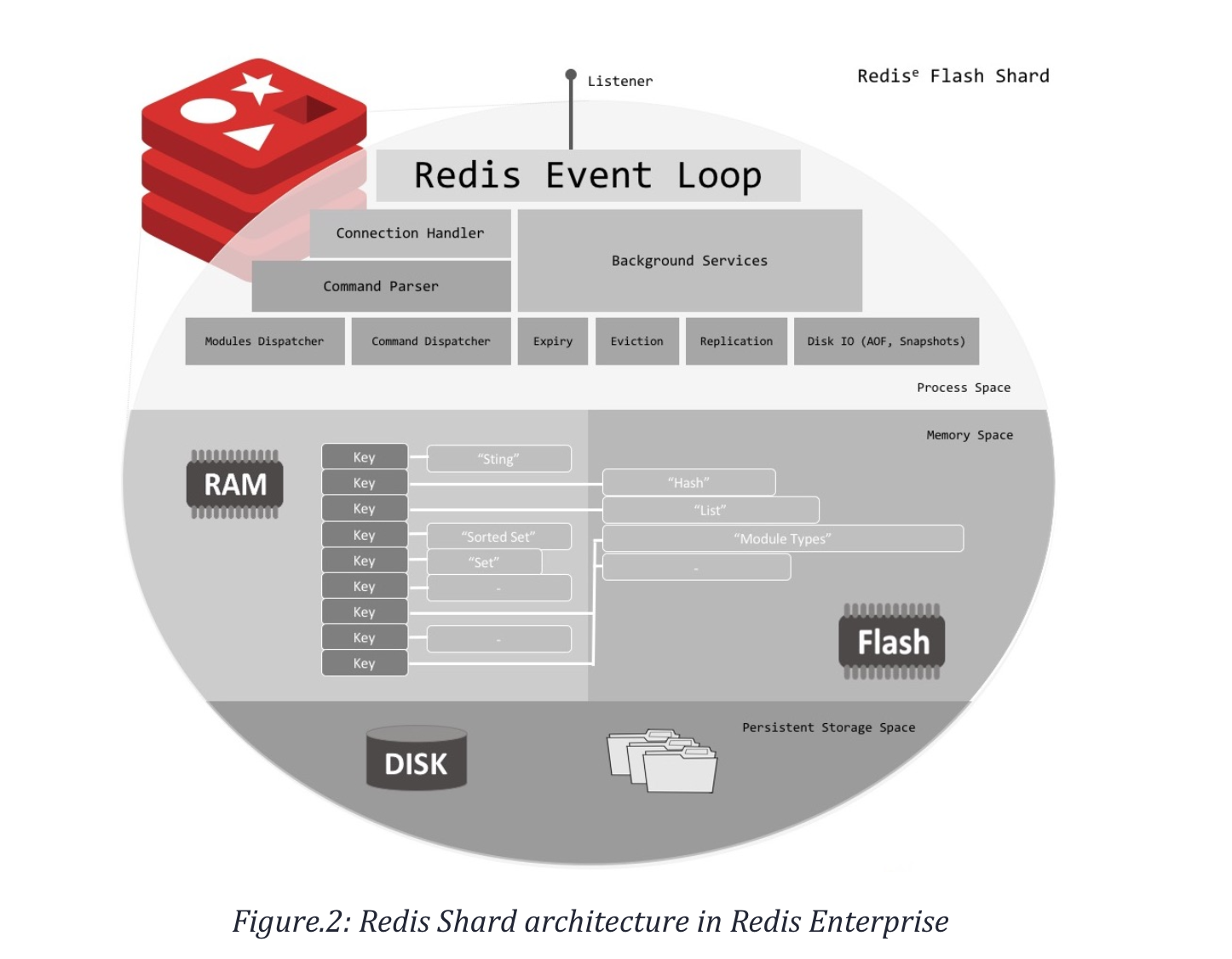
所有的key保存在内存,每个key都保存LFU信息,key的置换策略主要依赖LFU统计信息,将冷数据的value持久化到RocksDB,冷数据通过后台IO线程与RocksDB交互,不阻塞主线程。
4.2 线程模型
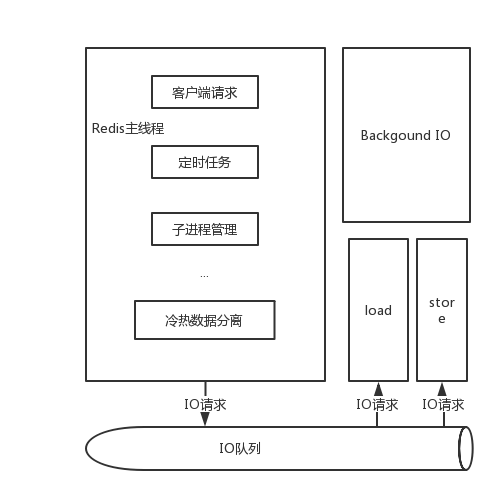
4.2.1 换出冷数据过程:
- server中增加一个maxhotmemory参数,当内存使用占用超过该配置,server会根据LFU或LRU等信息置换出合适的key;
- 将value decode成raw string,封装成异步IO任务,加入任务队列;
- IO线程取出异步任务,将key value存储到RocksDB;
- 处理完成后通知主线程,如果在异步线程未处理完成时,访问该key的客户端将加入等待队列;
- 主线程收到完成的通知后释放内存中value的内存;
- 唤醒等待该key的客户端。
4.2.2 加载冷数据过程:
- 客户端访问的key在置换队列中,需要将客户端加入等待队列;
- 访问的数据不在内存中,但是客户端命令类型不需要查询原有value,正常执行;
- 否则生成异步IO请求,放入IO队列;
- IO线程取出异步任务,从RocksDB中查询对应的value;
- 主线程将value加载到内存;
- 唤醒等待该key的客户端。
4.3 淘汰机制
增加maxcoldmemory参数,统计冷数据占用的空间,当maxmemory或maxcoldmemory达到阈值,就执行淘汰策略,与现有保持一致。
4.4 持久化
和原生的redis对比,持久化数据部分分为热数据和冷数据,热数据采用传统的aof或者rdb方式,冷数据采用RocksDB的checkpoint功能。
Checkpoint功能可以创建一个满足数据一致性的快照。如果snapshot所在的文件系统和DB file所在的文件系统相同的话,SST files会被硬链接,否则,就要全部拷贝过去,manifest和CURRENT files也会被拷贝过去。
RocksDB中的checkpoint的原理:
- 如果snapshot所在的文件系统和DB file所在的文件系统相同的话,SST files被硬链接;
- 否则需要进行文件拷贝;
- 拷贝manifest文件和CURRETN文件。
4.5 同步
同步过程也分为全量数据+增量数据过程。
4.5.1 全量同步
全量数据又有热数据和冷数据,热数据采用原有RDB加载逻辑进行同步,冷数据需要使用RocksDB的checkpoint功能,采用本地盘情况下,需要对checkpoint的文件进行物理拷贝。
- 从对主发起全量同步请求;
- master收到收创建rdb快照和RocksDB checkpoint;
- 创建完成后传输rdb和RocksDB checkpoint文件;
- 从收到文件后先打开RocksDB,然后加载rdb;
- 加载完成后同步增量数据。
4.5.2 增量同步
采用master异步发送output buffer方式,与现有策略保持一致。
4.6 集合类型处理方式
- 按单key处理
- 对集合类型value进行dump操作,生成二进制数据。
- 将key和二进制value数据写入RocksDB。
- 加载过程相反,读取二进制value,执行restore操作,加载到内存。
置换逻辑采用和普通key value同样策略,可以复用持久化部分逻辑,对于大集合key不友好,客户端阻塞。
- 按item处理
将不同的数据结构编码为kv结构, 按item存储。
- 在内存达到maxhotmemory上限,执行置换策略,如果key是集合,计算将部分item数据置换到RocksDB。
- 在一个集合中,key中保存所有item索引,置换到RocksDB的item做上特殊标记。
- 访问到特定item,判断item是否在内存中,若不在,RocksDB查询数据加载的内存。
置换逻辑复杂,各种数据结构单独持久化编码需要实现。
一期考虑采用单key处理方式,可以增加配置策略,对于大集合不会自动触发数据冷热迁移。
参考
- Running Out of RAM on Redis? No More OOM With Hybrid Memory (RAM and Flash) - DZone Performance
- Redis on Flash Overview - Redis Enterprise Software | Redis Labs
- Is Your Database Wasting the Ephemeral Drive? - DZone Database
- RedisConf17 - Building Large High Performance Redis Databases with Re…
- Optimization of RocksDB for Redis on Flash
- RocksDB: Key-Value Store Optimized for Flash-Based SSD
- Evaluation of High Performance Key-Value Stores
- Anna Cluster Paper
- Pika is a nosql compatible with redis
- Application data caching using SSDs – Netflix TechBlog – Medium
- Redis混合存储产品与架构介绍-博客-云栖社区-阿里云
- Checkpoints · facebook/rocksdb Wiki