昨天被朋友圈的一片软文刷屏了,秒杀Redis的KVS上云了!伯克利重磅开源Anna 1.0 什么秒杀,吊打。。。这种小编是标题骗点击,着实无语。
做技术都应该抱着敬畏的心态,不同的系统都是在特定的应用场景下诞生的,每一个系统都可能是某一种应用场景下的No.1, 任何系统,特别是存储类系统,没有一个能够普适的系统完美应对各种应用场景。
一直对一句话非常赞同:“通用的结果就是通通不能用”。
在半年之前就看到过HN上关于Anna的消息,也是很多人看到论文中关于和Cassandra、Elasticache、MessTree等对比的argue。
Claims in the blog post (orders of magnitude faster than the current state of the art systems, universal linear universal scalability from threads to many nodes, dimissing Dean’s rule of redesign after x10 scale) seem overblown to me. What have they really built: a purely in-memory KV store that doesn’t support synchronous secondary writes for durability. So, any comparisons with ACID KV stores, either disk based (Cassandra, Mongo) or in-memory, are not apples-to-apples comparisons from the beginning. What could be production applications of such system, other than cache?
这次发表的论文主要是对Anna集群化的一些工作,描述了如何实现分布式系统的扩展性、低成本和热点问题。
简单过了一下Anna kvs的集群化上云的论文,简单记录了一下比较关心的点。
Anna特性:
- 水平无限扩展
- 数据分层移动,冷热数据分离,降低成本
- 热点数据流量动态调整
部署&架构
基于aws云组件构建,存储节点有内存和亚马逊块存储挂载盘。
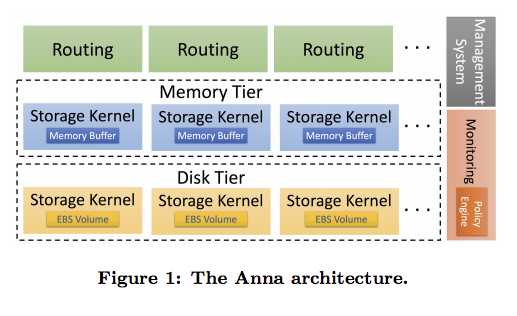
- 监控系统组件,无状态
- 策略系统组件,无状态,完成一些数据部署放置策略、数据冷热分离策略、热点key策略
- 路由组件,无状态,路由的实现不同于proxy,用户请求流量不经过路由组件,路由组件只提供客户端key的信息,客户端可以对路由信息进行缓存,当数据分布更新后,路由服务会自动更新其缓存的路由信息,供客户端查询。集群的数据迁移,数据分层的变化,通过路由服务进行屏蔽了底层细节,它能够准确的返回给客户端数据的所在的节点和层次。
- 存储组件,存储节点根据后端的存储介质区分所在的层次,是单纯的key value引擎,使用gossip协议数据异步复制,支持多master写入,采用
last update win策略解决数据冲突,多线程模式shared-nothing数据架构。
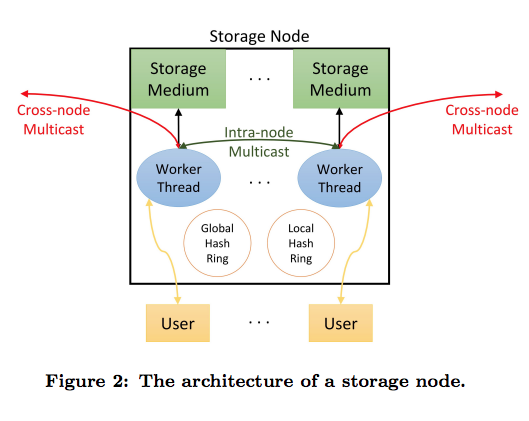
Anna的数据分布采用一致性hash,中间加了一层虚拟节点,类似redis cluster中的slot,虚拟节点就是key的子集,一个物理节点负责多个虚拟节点。
- 数据和分布解耦
- 数据运维单位粒度更小
- 物理节点异构
存储层
为了性能,采用了多work线程架构,支持多master写入,数据的更新直接更新本地,数据的复制依靠后台gossip协议分发。多master所带来的问题就是不能简单对写入的数据进行转发,同时在不同节点更新同一个数据,采用CRDT数据结构来处理数据冲突。
数据迁移过程中客户端读取数据可能不准确,会读到旧数据,感觉这个完全通过一定策略来避免。

数据冷热变化后在不同层次之间的移动所采用的方式比较优雅,就是通过只key对应的meta信息中的replication vector实现数据的移动,异步由gossip协议来进行数据的迁移过程
元数据
- Global hash ring:保存key到node的映射
- Local hash ring:保存key到一个node节点内部worker thread的映射
- Replication vector:[<R1,…RN>,<T1,…TN>],保存的是每个key所对应的复制集节点和worker thread
和大部分集中化配置的分布式系统不同,上述元数据不需要保存类似zk、etcd等系统中,直接保存在底层的kv存储,不依赖外部系统。
策略
Anna可以配置三种SLO策略维度:
- 延迟
- 预算
- 可用性
集群规模的变更会导致数据的迁移,数据迁移过程中为了避免影响服务,Anna也不得不加入grace periods,在这个时间段内,系统存在一定的降级策略,key的冷热数据管理、热点key复制和扩展性的功能都是不可用的。
总结
Anna中实现的这几个特性是比较有需求的,特别是冷热数据分离和热点key的处理,提升单实例的性能一般也会采用多线程方式。
冷热数据分离就像上一篇提到的,要尽量做到用户无感知的情况下达到节省成本的目标,Anna论文中在futrue work中提到了,当前的策略,采用的是根据当前系统状态或统计信息,来做下一步的操作,比如读取冷数据,对于客户端而言,肯定能感知到延时的增加。所以后续可能通过预测的方式来使系统变的更智能,那样,冷数据会提前变为热数据,达到对客户端透明。
热点key的数据方式依赖了多master架构,数据的冲突解决采用类似CRDT数据结构来处理冲突,保证数据最终一致,这样的实现方式可能会带来客户端读取到旧数据,或者幻读的问题。
参考