今天在hn上看到阿里的PolarFS论文,简单读了一下,感觉分布式系统整体架构就是江湖,分久必合,合久必分。
分布式系统的架构不外乎两种,一种是中心化配置,一种是非中心化配置。
中心化配置的系统比较多,像GFS/HDFS/集群化MongoDB/TiKV等系统,组件主要是三种,存储节点、控制节点和路由节点。
- 存储节点的实现根据系统要解决的问题可以实现为AP或CP,异步数据复制或者类paxos实现一致性复制
- 路由节点可以是类似mongos的作用类似proxy,client不需要知晓集群内部细节,客户端更加轻量级;在GFS系统中这部分就集成在client端,client就需要对请求进行路由
- 控制节点一般完成的工作包括数据的分布维护、集群中节点状态维护、集群高可用控制、数据的迁移控制等,可能会做一些元信息维护和触发一些周期性任务
非中心化配置的像Redis cluster、Cassandra、Scylla、Dynamo,其主要组件主要就是存储和路由控制。
这些系统中,一般不需要控制节点,集群的状态会通过一些分布式协议如gossip,在集群内部进行传播,集群内部所有节点地位是对等,每个节点都有集群完整的数据分布信息,请求任意节点即可完成交互。系统中可能也不需要路由节点,路由节点功能会集成在数据节点或者智能客户端,客户端动态获取并缓存数据分布状态信息,完成数据定位。
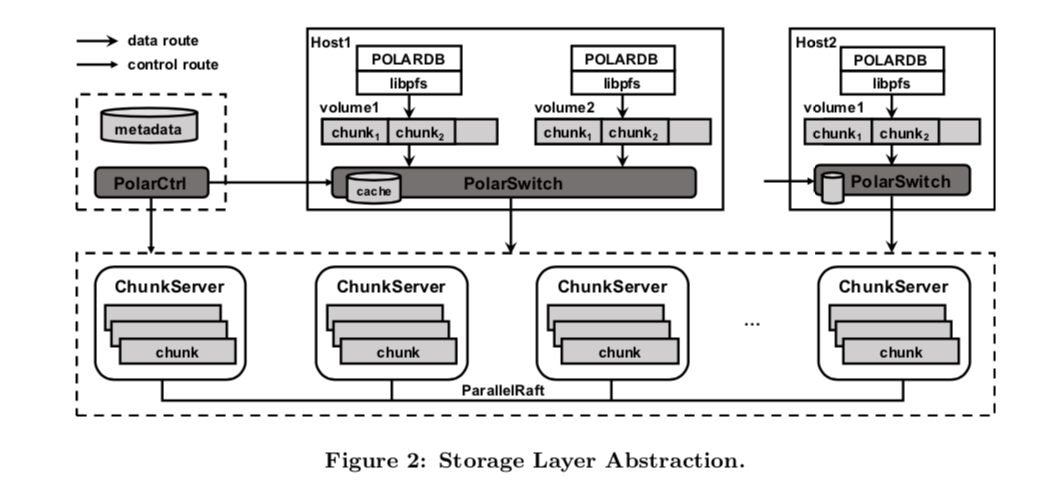
PolarFS整体架构也没有特别之处,和GFS、HDFS非常像,也是集中化配置,其中的PolarCtrl是控制节点、PolarSwitch是路由节点、ChunkServer就是数据节点,其特别之处是通过使用新硬件设备(NVMe),和技术(实现用户态网络和IO操作,intel的SPDK,RDMA,优化的raft协议等)来压榨硬件性能,尽可能降低分布式系统中最要命的问题–延时,包括操作系统陷入内核IO操作导致的延时,网络IO延时,数据同步延时。
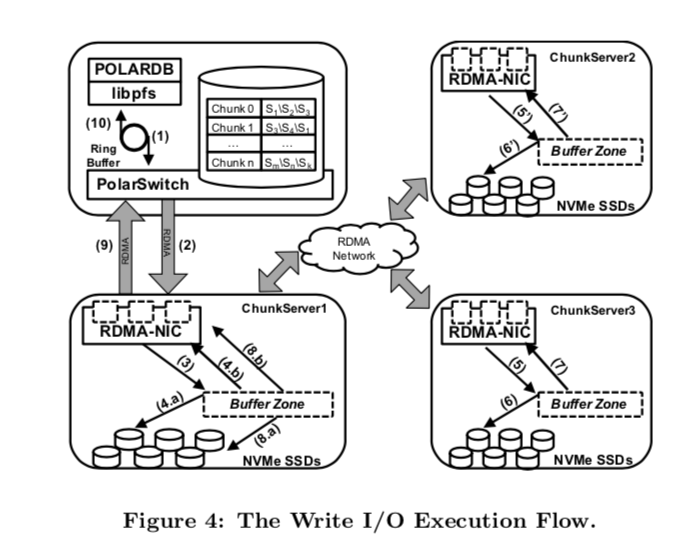
用户态实现了类似posix语义的操作,这些操作不是标准库的系统调用,不会陷入内核,纯用户态操作,操作指令通过RDMA方式发送给对应chunk server。
数据复制采用优化过的ParrallelRaft,加快复制,这部分细节没有看。
PolarCtrl中对于源信息的管理中采用Disk paxos协议和journal file保证元数据信息高可用和安全性。
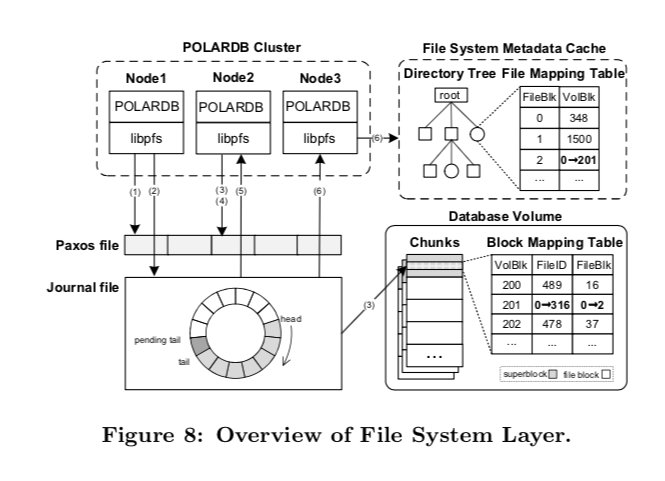
Polar通过一种打tag的方式,通过copy on write实现了快照功能。
最后给出的性能对比中,整体看IO latency能达到和本地文件系统同一数据量级,性能远好于Ceph FS,吞吐量基本上可以和本地ext4持平,远好于Ceph FS。
PolarFS底层分布式文件系统,在其上构建分布式数据库会更简单,因为采用计算存储分离架构,计算层不需要考虑数据复制和安全性,这些有底层分布式文件系统保证,上层应用只需要关注数据操作逻辑,实现复杂度也极大降低,TiDB和Tidis的实现的逻辑也是类似,底层实现的分布式kv引擎,完成了数据复制和水平扩展,上层的实现的复杂度极大的降低,当然也存在任何分布式系统都存在的高延时问题,这就需要像PolarFS中努力通过新的技术来压榨新硬件的极限性能。
参考